Benchmarking LLM Retrieval on Semi-structured Knowledge Bases
Welcome to STaRK!
STaRK is a large-scale Semi-structured Retrieval Benchmark on Textual and Relational Knowledge bases, covering applications in product search, academic paper search, and biomedicine inquiries.
Featuring diverse, natural-sounding, and practical queries that require context-specific reasoning, STaRK sets a new standard for assessing real-world retrieval systems driven by LLMs and presents significant challenges for future research.
Why STaRK?
Novel and Realistic Task
STaRK uniquely assesses LLMs' ability to handle complex retrieval tasks in semi-structured knowledge bases, a domain where their effectiveness remains largely unexplored.
Large-scale and Diverse Knowledge
STaRK offers a diverse span of semi-structured knowledge, presenting a broad spectrum of information that challenges the capabilities of LLMs.
Natural-sounding and Practical Queries
STaRK features queries that mimic real-world scenarios, combining complex relational and textual requirements in natural-sounding forms to evaluate LLMs.
STaRK Workflow
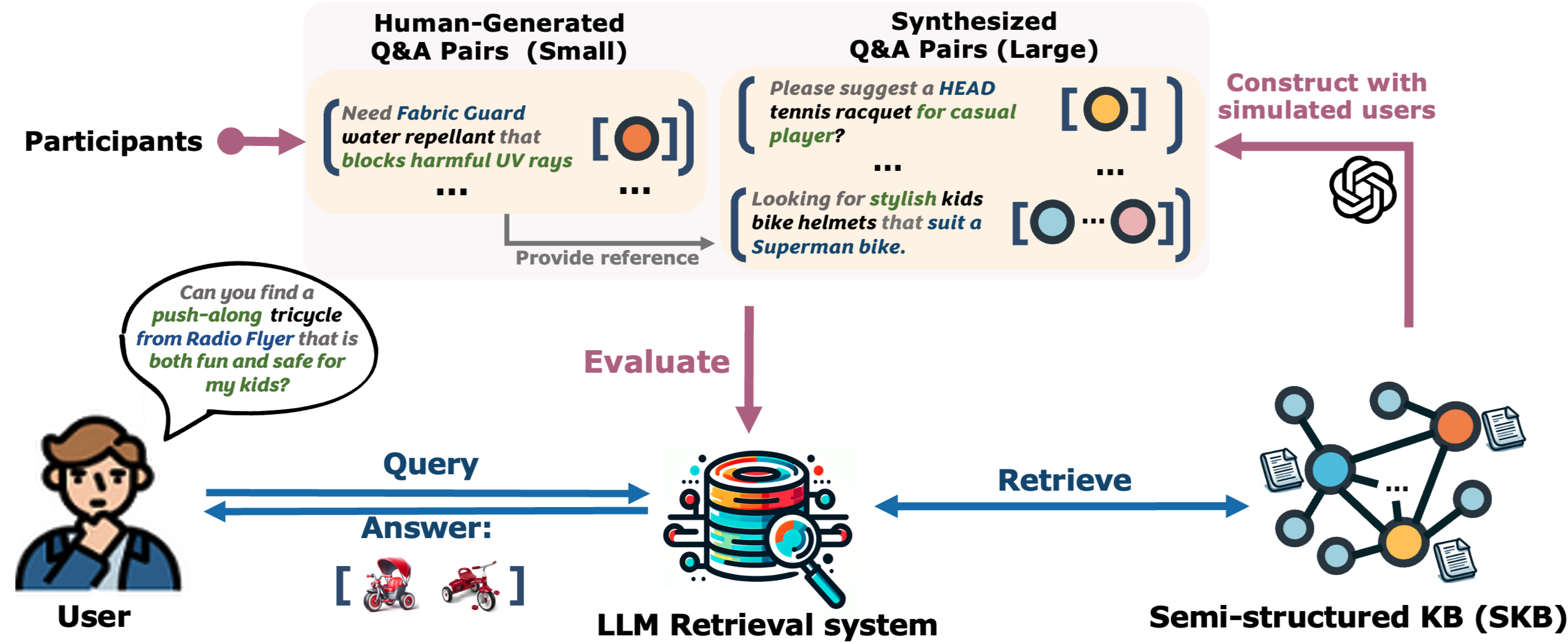
Downstream Task: Retrieval systems driven by LLMs are tasked with extracting relevant answers from a Semi-structured Knowledge Base (SKB) in response to user queries.
Benchmarking: To evaluate model performance on SKB retrieval tasks, STaRK includes:
1) Synthesized queries that simulate real-world user requests,
2) Human-generated queries for authentic benchmarks and evaluation,
3) Precisely verified ground truth answers/nodes through automatic and manual filtering.